]]>Jasper (Jintao Chen)cjt@stu.pku.edu.cnAstraNav-World: World Model for Foresight Control and Consistency2025-12-25T00:00:00+00:002025-12-25T00:00:00+00:00https://jasperchennn.github.io/astranav-world-en
Note: this is the English version paired with the Chinese post
AstraNav-World: World Model for Foresight Control and Consistency.
Abstract
We propose AstraNav-World, an end-to-end world model for embodied navigation
in open and dynamic environments. The model unifies multi-step visual prediction
and action sequence reasoning into a single probabilistic framework by combining
diffusion-based video generation with a vision-language policy. A bidirectional
constraint mechanism enforces both the executability of predicted futures and the
physical consistency of actions, which largely mitigates error accumulation in
the traditional “predict-then-plan” pipeline. Experiments on diverse navigation
benchmarks show improved trajectory accuracy and task success rate, and the model
exhibits strong zero-shot generalization in real-world tests.
Introduction
Here you can briefly motivate:
Why foresight control is crucial for embodied agents in open worlds;
Limitations of decoupled prediction and planning pipelines;
The target audience (CV / robotics / embodied AI researchers and engineers).
Method
1. Problem Definition
Clearly state the embodied navigation setting and evaluation protocol, and
define what “foresight control” and “consistency” mean in this work.
2. Approach
Describe the AstraNav-World architecture:
multi-module design combining diffusion video generator and VL policy;
training objectives for action-conditioned visual prediction and
policy learning;
bidirectional constraints that tie predicted futures to executable actions.
3. Experiments
Summarize:
benchmarks, metrics and baselines;
ablations on each key module and training objective;
zero-shot transfer from simulation to real-world environments.
4. Results and Analysis
Discuss:
trajectory and success-rate improvements;
what happens when coupling between vision and action is removed;
qualitative examples that illustrate better foresight and consistency.
Conclusion and Future Work
Highlight the main takeaways and outline:
deployment to real robots;
extension to interaction / manipulation tasks;
richer multi-modal inputs and better interpretability.
]]>Jasper (Jintao Chen)cjt@stu.pku.edu.cnAstraNav-World: World Model for Foresight Control and Consistency2025-12-25T00:00:00+00:002025-12-25T00:00:00+00:00https://jasperchennn.github.io/astranav-world-zh个人小结
]]>Jasper (Jintao Chen)cjt@stu.pku.edu.cnOmni-Effects: Unified and Spatially-Controllable Visual Effects Generation2025-08-11T00:00:00+00:002025-08-11T00:00:00+00:00https://jasperchennn.github.io/omini-effects-xfx-en
Note: this is the English version paired with the Chinese post
Omni-Effects: Unified and Spatially-Controllable Visual Effects Generation.
Abstract
Visual effects (VFX) are central to modern video and film production.
Although recent video generation models enable low-cost VFX creation, they
are typically trained with single-effect LoRA adapters and therefore cannot
produce multiple effects at user-specified locations. To address cross-effect
interference and the lack of spatial controllability in joint multi-VFX training,
we propose Omni-Effects, the first unified framework for prompt-driven and
spatially controllable composite VFX generation. The core design includes:
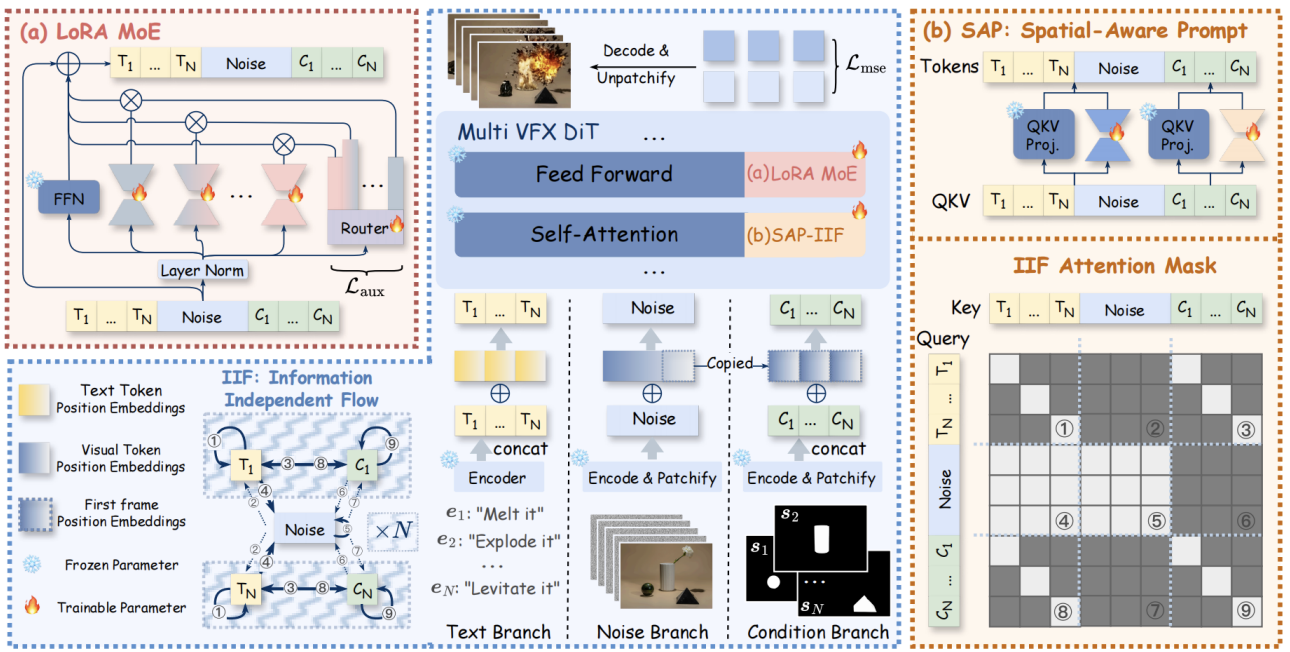
1) a LoRA-based Mixture-of-Experts (LoRA-MoE) module that integrates diverse
effects in a single model while alleviating inter-task interference; and
2) a Spatial-Aware Prompt (SAP) module that injects spatial masks into text
tokens for precise spatial control, equipped with an Independent-Information
Flow (IIF) submodule to isolate control signals of different effects and avoid
unwanted blending. We further construct the Omni-VFX dataset and a dedicated
VFX evaluation protocol. Extensive experiments demonstrate that Omni-Effects
achieves accurate spatial control and diverse, high-quality effects, supporting
user-defined effect types and locations.
Introduction
Briefly introduce:
the role and cost of traditional VFX production;
limitations of single-effect LoRA-based methods for real-world workflows;
the need for unified, spatially-controllable multi-effect generation.
Method
1. Problem Definition
Formulate unified VFX generation with:
multiple effect types;
user-specified spatial regions;
quality, independence and controllability requirements.
2. Approach
Describe:
the LoRA-MoE module: expert design, routing / combination strategy and
how it reduces cross-effect interference;
the SAP module: how spatial masks are embedded into prompts;
the IIF design: how information flow is separated across effects.
3. Data and Training
Summarize the Omni-VFX dataset construction pipeline and the training setup
for the unified model.
4. Results and Analysis
Highlight:
single-effect quality vs. single-LoRA baselines;
spatial accuracy compared with existing editing / generation methods;
independence of multiple effects on the same frame.
Conclusion and Future Work
Summarize the contributions and outline:
extension to higher-resolution and production-grade VFX;
]]>Jasper (Jintao Chen)cjt@stu.pku.edu.cn[CVPR]UniEdit-I: Training-free Image Editing for Unified VLM via Iterative Understanding, Editing and Verifying2025-08-05T00:00:00+00:002025-08-05T00:00:00+00:00https://jasperchennn.github.io/uniedit-zh个人小结
]]>Jasper (Jintao Chen)cjt@stu.pku.edu.cn[ICLR2026] NarrLV: Towards a Comprehensive Narrative-Centric Evaluation for Long Video Generation Models2025-07-15T00:00:00+00:002025-07-15T00:00:00+00:00https://jasperchennn.github.io/narrlv-zh个人小结
]]>Jasper (Jintao Chen)cjt@stu.pku.edu.cn[CVPR2025]Decouple Distortion from Perception: Region Adaptive Diffusion for Extreme-low Bitrate Perception Image Compression2025-06-17T00:00:00+00:002025-06-17T00:00:00+00:00https://jasperchennn.github.io/en/region-adaptive-diffusion-compression-enAbstract
Generative image compression leverages the generative capabilities of diffusion models to achieve excellent perceptual fidelity at extreme-low bitrates. However, existing methods overlook the non-uniform complexity of images, making it difficult to balance global perceptual quality with local texture consistency and to achieve efficient allocation of coding resources. To address this issue, this paper proposes the Map-guided Masked Realistic Image Diffusion Codec (MRIDC), which aims to optimize the trade-off between local distortion and global perceptual quality in extreme-low bitrate compression. MRIDC integrates a vector-quantized image encoder with a diffusion-based decoder. At the encoding stage, the Map-guided Latent Masking (MLM) module enables adaptive resource allocation based on image complexity. At the decoding stage, the Bidirectional Prediction Controllable Generation (BPCG) module completes masked latent variables and reconstructs images. Experimental results demonstrate that MRIDC achieves state-of-the-art (SOTA) perceptual compression quality at extreme-low bitrates, effectively preserving feature consistency in key regions, advancing the perceptual rate-distortion performance curve, and establishing a new benchmark for balancing compression efficiency and visual fidelity.
Introduction / Background
In scenarios such as the Internet of Things (IoT), edge computing, and real-time visual transmission, extreme-low bitrate image compression has become a core requirement. It not only needs to achieve high compression ratios to save transmission and storage resources but also ensure the perceptual quality of images and feature consistency in key regions. Generative diffusion models have brought new breakthroughs to extreme-low bitrate image compression, significantly improving the perceptual fidelity of compressed images. However, existing diffusion-based compression methods have a core flaw: treating images as uniform entities for encoding and reconstruction, ignoring the complexity differences in different regions of images.
This flaw leads to unbalanced allocation of coding resources—simple regions occupy excessive resources while complex key regions lack sufficient resources. Ultimately, this results in acceptable global perceptual quality but local texture distortion and loss of key features, making it difficult to meet the requirements of visual perception tasks for image details. Meanwhile, there is still room for optimization in the rate-distortion perception trade-off of existing methods, and the precise balance between compression efficiency and visual fidelity has not yet been achieved.
Targeting researchers, engineers, and practitioners in the fields of image compression, computer vision, and multimedia processing, this paper proposes a region-adaptive diffusion-based image compression framework to solve the problems of uneven resource allocation and local distortion in existing methods, providing a new solution for extreme-low bitrate perceptual image compression. This work is published at CVPR 2025, representing a top conference research achievement in the field of generative image compression.
Methodology / Main Content
1. Problem Definition
This research focuses on the perceptual image compression problem at extreme-low bitrates. The core objective is to address the issues of inefficient coding resource allocation, local texture distortion, and inconsistent key region features in existing diffusion-based generative compression methods caused by ignoring the non-uniform complexity of images. We aim to achieve triple optimization of global perceptual quality, local texture consistency, and compression efficiency, thereby improving the comprehensive perceptual rate-distortion performance.
2. Solution Approach / Theoretical Derivation
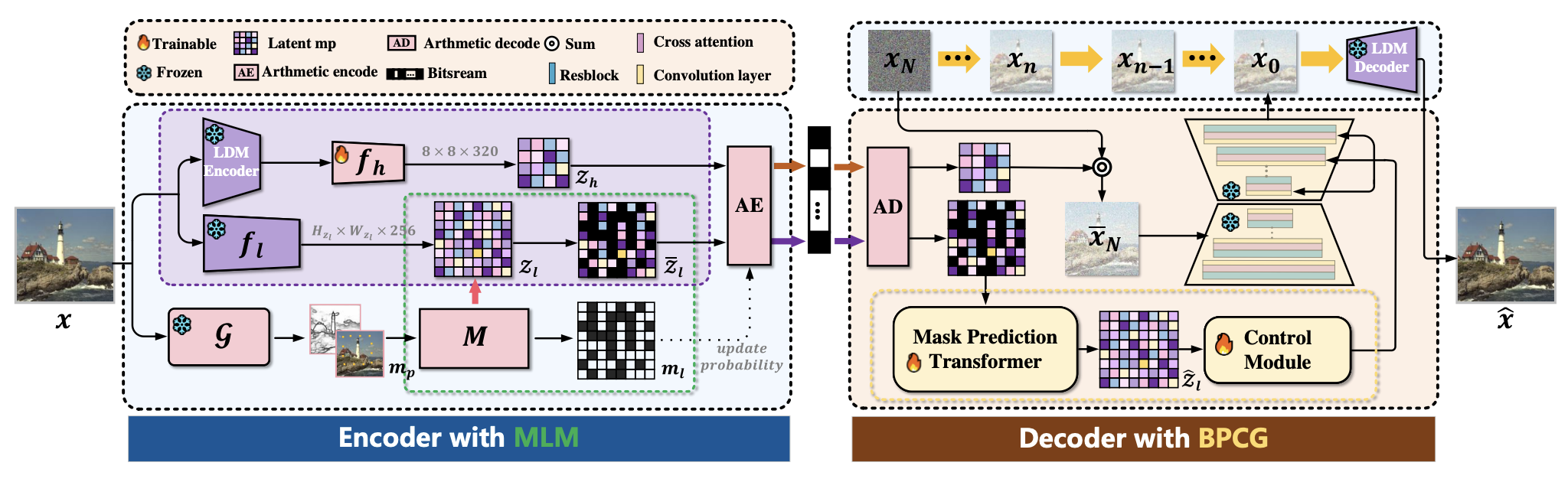
We propose the Map-guided Masked Realistic Image Diffusion Codec (MRIDC), whose core idea is to decouple distortion and perceptual quality in image compression through region-adaptive coding resource allocation and constrained diffusion reconstruction, achieving a precise trade-off between them. The overall architecture is a joint design of a vector-quantized encoder + diffusion-based decoder, with core modules including:
Map-guided Latent Masking (MLM) Module (Encoding Stage): Based on prior information of image complexity, selectively masks the latent space to retain more latent variable information for complex/key regions and mask more redundant information for simple regions, realizing adaptive allocation of coding resources and improving resource utilization efficiency;
Bidirectional Prediction Controllable Generation (BPCG) Module (Decoding Stage): Adds constraint guidance to the generation process of the diffusion model, bidirectionally predicts and completes masked latent variables based on unmasked latent variable information, achieves constrained image reconstruction, and ensures local texture consistency and fidelity of key features.
MRIDC整体框架
3. Experimental Setup / Implementation Details
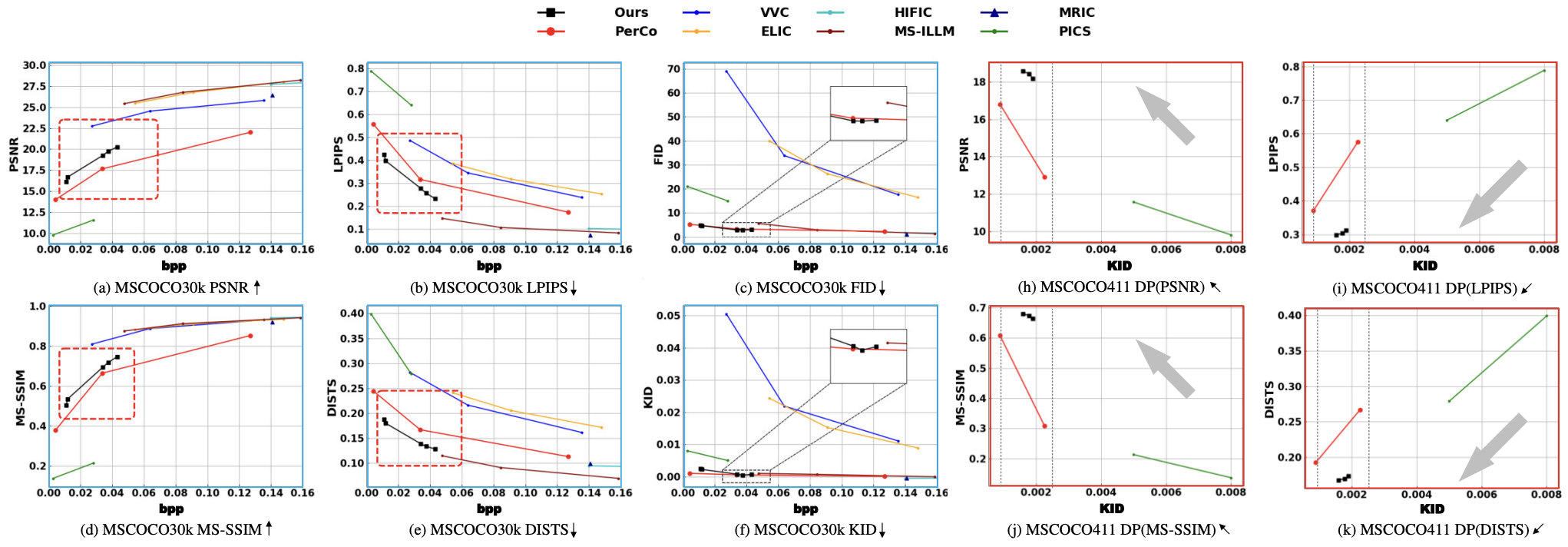
Experimental Benchmarks: Experiments are conducted on mainstream public datasets for extreme-low bitrate image compression, comparing with current SOTA generative image compression methods and traditional compression methods;
Evaluation Metrics: Comprehensive evaluation from three dimensions: perceptual quality (e.g., LPIPS, SSIM, subjective MOS scores), rate-distortion performance (RD curves), and key region feature consistency;
Core Verification: Verify the region-adaptive resource allocation effect, local texture reconstruction capability, and generalization performance of MRIDC at different extreme-low bitrates.
4. Results and Analysis
SOTA Performance Verification: MRIDC achieves state-of-the-art perceptual compression quality at extreme-low bitrates, significantly outperforming comparison methods in objective metrics such as LPIPS, SSIM, and subjective MOS scores;
Key Region Fidelity: Through region-adaptive resource allocation and constrained reconstruction, the model effectively preserves feature consistency in key image regions, solving the problems of local texture distortion and feature loss in existing methods;
Rate-Distortion Perception Optimization: The model significantly advances the perceptual rate-distortion performance curve, achieving higher perceptual quality at the same bitrate and lower bitrate at the same perceptual quality, establishing a new industry benchmark for balancing compression efficiency and visual fidelity;
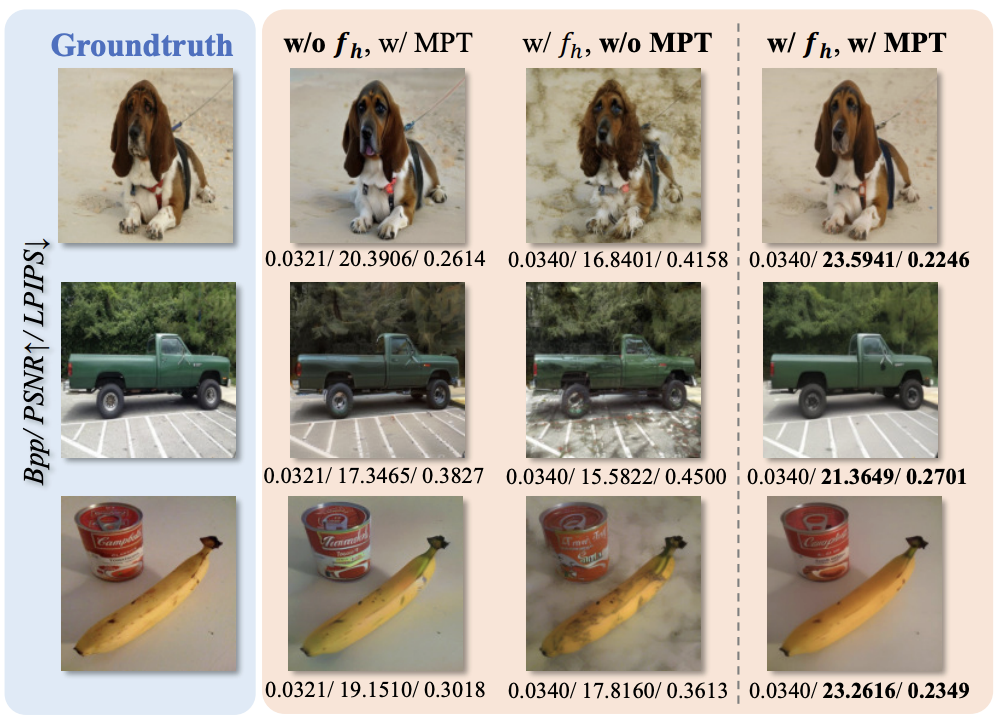
Module Effectiveness: Ablation experiments verify the necessity of the core modules MLM and BPCG. Removing either module leads to decreased resource allocation efficiency, reduced perceptual quality, and lower local consistency.
results
Conclusion and Outlook
Key Contributions
Proposed the Map-guided Masked Realistic Image Diffusion Codec (MRIDC), integrating region-adaptive resource allocation into diffusion-based generative image compression for the first time, decoupling distortion and perceptual quality in compression, and solving the core problem of uneven resource allocation in existing methods;
Designed dedicated modules MLM (encoding stage) and BPCG (decoding stage), realizing end-to-end optimization from latent variable masking to constrained reconstruction, ensuring dual improvement of global perceptual quality and local texture consistency at extreme-low bitrates;
Published at CVPR 2025, MRIDC achieves SOTA performance in extreme-low bitrate perceptual image compression, advancing the perceptual rate-distortion performance curve and establishing a new benchmark for balancing compression efficiency and visual fidelity.
Personal Notes
It was not noticed at that time that a series of subsequent visual tokenizers all adopted similar dual-encoder structures. Unfortunately, only compression and reconstruction were explored at that time, without investigating the generation aspect.
]]>Jasper (Jintao Chen)cjt@stu.pku.edu.cn[CVPR2025]Decouple Distortion from Perception: Region Adaptive Diffusion for Extreme-low Bitrate Perception Image Compression2025-06-17T00:00:00+00:002025-06-17T00:00:00+00:00https://jasperchennn.github.io/region-adaptive-diffusion-compression-zh个人小结
生成式图像压缩借助扩散模型的生成能力,在极低码率下已实现优异的感知保真度,但现有方法忽略了图像的非均匀复杂度,难以平衡全局感知质量与局部纹理一致性,也无法实现编码资源的高效分配。为此,本文提出地图引导掩码真实感图像扩散编解码器(MRIDC),旨在优化极低码率压缩中局部失真与全局感知质量的权衡关系。MRIDC整合了向量量化图像编码器与扩散基解码器,在编码端设计地图引导潜变量掩码(MLM)模块实现基于图像复杂度的自适应资源分配,解码端通过双向预测可控生成(BPCG)模块完成掩码潜变量的补全与图像重建。实验结果表明,MRIDC在极低码率下取得了 sota 级的感知压缩质量,有效保留了关键区域的特征一致性,推动了率失真感知性能曲线的提升,为平衡压缩效率与视觉保真度建立了新基准。